DatabricksWorkflowTaskGroup¶
使用 DatabricksWorkflowTaskGroup 将 Databricks notebook 作业运行作为 Airflow 任务启动和监控。此任务组启动一个 Databricks Workflow 并在其中运行 notebook 作业,与在 DatabricksWorkflowTaskGroup 之外执行 DatabricksNotebookOperator 相比,可降低 75% 的成本(通用计算为 $0.40/DBU,作业计算为 $0.07/DBU)。
在 Airflow 中定义 Databricks Workflows 有一些优势
创作界面 |
通过 Databricks (基于 Web 的 Databricks UI) |
通过 Airflow (使用 Airflow DAG 代码) |
|---|---|---|
Workflow 计算定价 |
✅ |
✅ |
源代码控制中的 Notebook 代码 |
✅ |
✅ |
源代码控制中的 Workflow 结构 |
✅ |
✅ |
从头开始重试 |
✅ |
✅ |
重试单个任务 |
✅ |
✅ |
Workflows 中的任务组 |
✅ |
|
从其他 DAG 触发 workflows |
✅ |
|
Workflow 级别参数 |
✅ |
示例¶
带有 DatabricksWorkflowTaskGroup 的 DAG 示例¶
tests/system/databricks/example_databricks_workflow.py
task_group = DatabricksWorkflowTaskGroup(
group_id=f"test_workflow_{USER}_{GROUP_ID}",
databricks_conn_id=DATABRICKS_CONN_ID,
job_clusters=job_cluster_spec,
notebook_params={"ts": "{{ ts }}"},
notebook_packages=[
{
"pypi": {
"package": "simplejson==3.18.0", # Pin specification version of a package like this.
"repo": "https://pypi.ac.cn/simple", # You can specify your required Pypi index here.
}
},
],
extra_job_params={
"email_notifications": {
"on_start": [DATABRICKS_NOTIFICATION_EMAIL],
},
},
)
with task_group:
notebook_1 = DatabricksNotebookOperator(
task_id="workflow_notebook_1",
databricks_conn_id=DATABRICKS_CONN_ID,
notebook_path="/Shared/Notebook_1",
notebook_packages=[{"pypi": {"package": "Faker"}}],
source="WORKSPACE",
job_cluster_key="Shared_job_cluster",
execution_timeout=timedelta(seconds=600),
)
notebook_2 = DatabricksNotebookOperator(
task_id="workflow_notebook_2",
databricks_conn_id=DATABRICKS_CONN_ID,
notebook_path="/Shared/Notebook_2",
source="WORKSPACE",
job_cluster_key="Shared_job_cluster",
notebook_params={"foo": "bar", "ds": "{{ ds }}"},
)
task_operator_nb_1 = DatabricksTaskOperator(
task_id="nb_1",
databricks_conn_id=DATABRICKS_CONN_ID,
job_cluster_key="Shared_job_cluster",
task_config={
"notebook_task": {
"notebook_path": "/Shared/Notebook_1",
"source": "WORKSPACE",
},
"libraries": [
{"pypi": {"package": "Faker"}},
],
},
)
sql_query = DatabricksTaskOperator(
task_id="sql_query",
databricks_conn_id=DATABRICKS_CONN_ID,
task_config={
"sql_task": {
"query": {
"query_id": QUERY_ID,
},
"warehouse_id": WAREHOUSE_ID,
}
},
)
notebook_1 >> notebook_2 >> task_operator_nb_1 >> sql_query
通过此示例,Airflow 将生成一个名为 <dag_name>.test_workflow_<USER>_<GROUP_ID> 的作业,该作业将运行任务 notebook_1,然后运行 notebook_2。如果该作业尚不存在,将在 databricks 工作区中创建。如果作业已存在,将进行更新以匹配 DAG 中定义的 workflow。
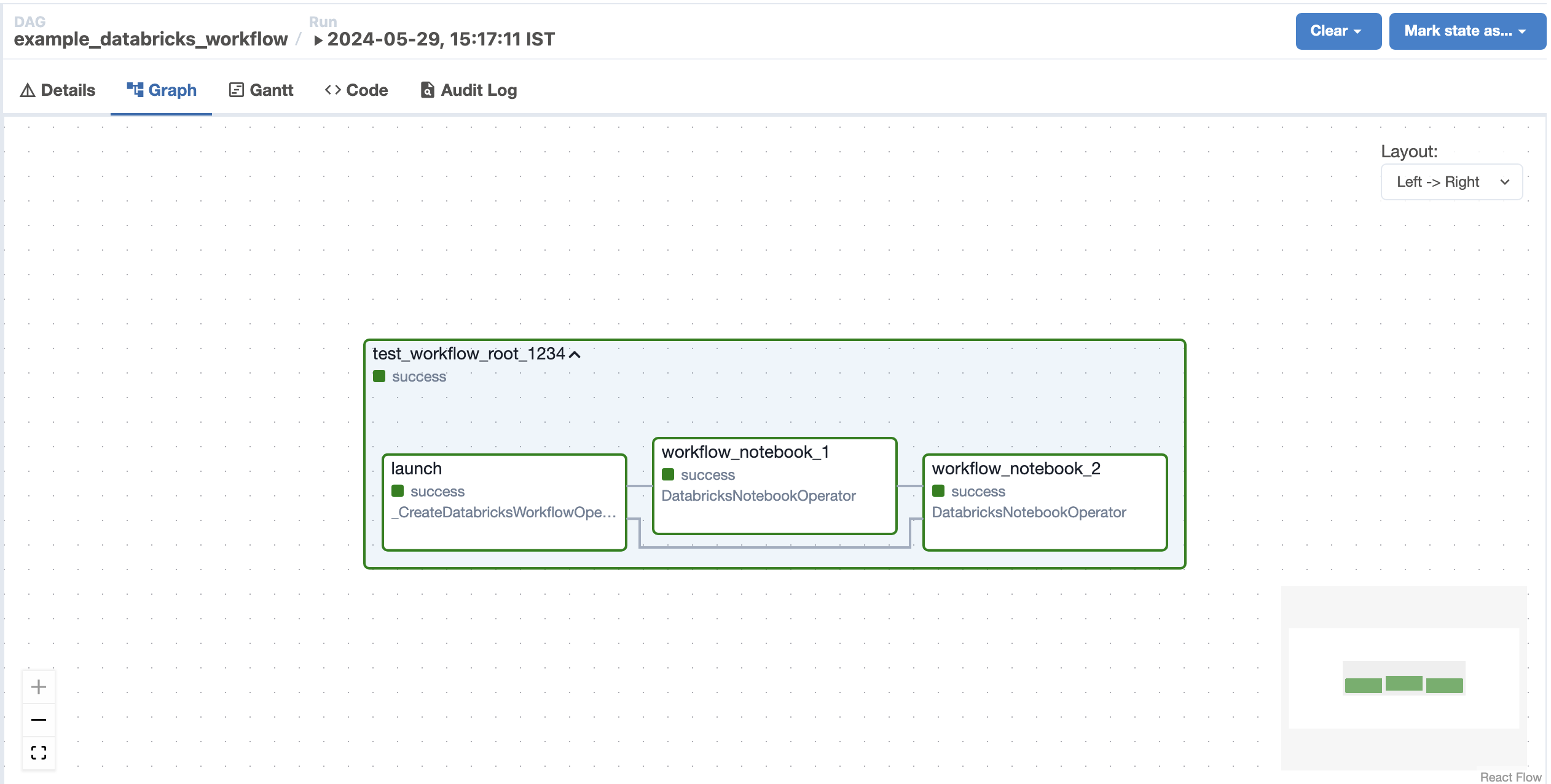
下图显示了 Airflow UI 中生成的 Databricks Workflow (基于上面提供的示例)¶
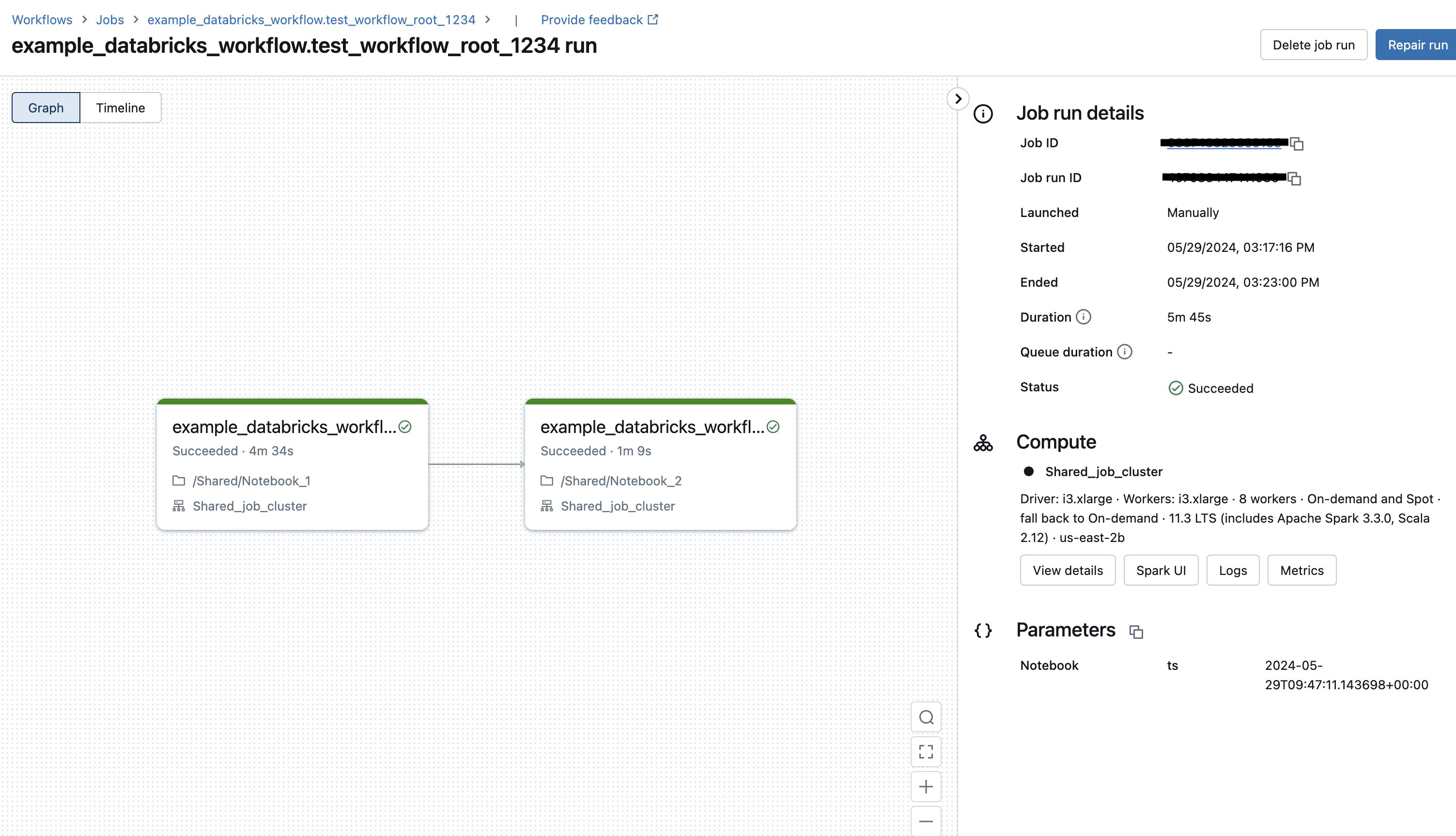
下面显示了从 Airflow DAG 触发的运行在 Databricks UI 中对应的 Databricks Workflow¶
为尽量减少更新冲突,我们建议您在可能的情况下将参数保存在 DatabricksWorkflowTaskGroup 的 notebook_params 中,而不是在 DatabricksNotebookOperator 中。这是因为 DatabricksWorkflowTaskGroup 中的任务在作业触发时传入,并且不会修改作业定义。